
Elbow-deep in bytes - extracting assets from demos
By Gargaj / Ümläüt Design ^ Conspiracy
"...see how deep this rabbithole goes..."
If you happen to browse Pouet, reading comments for demos, a surprisingly numerous amount of threads will feature requests for a direct download link for the soundtrack of the production. This is amusing when the music is right next to the demo in a data directory, but also very thought-provoking when the soundtrack is jammed into a datafile and the requesting person in question is a coder. It might be just me being a hardliner in the case, but I do think a demoscene coder should be able to reverse engineer a datafile to a level of extracting resources from it. In the following article, I'll provide a short walkthrough for a possible way of decompiling a datafile.
Disclaimer
The following article is intended for educational purposes only. It is NOT intended to condone or encourage ripping assets from existing demos and reusing them in other productions. Consider it a privilege that you can decompile a demo, not a right. I accept no responsibility for the use of the below knowledge.
Concept
So what are datafiles? Datafiles are large files that are used as a container for smaller files, for the purpose of encapsulation, encryption, convenience and elegance. They can be, in fact (and with a little nudge-nudge), called custom basic file-systems: they usually contain a table with filenames, offsets and sizes describing other files included. This, mind you, isn't a necessary option - there are demos which simply omit either the filename or even the complete table, but more often than not, they don't, simply because it's extremely convenient to work this way: when a file changes in your demo, you just whack together your datafile again, and all the data that's needed is automatically updated in the header tables. All your demo has to do is look up the filename, read the offset and length next to it and load up the data accordingly. A very very clean and enjoyable way of working. (A little note if you have your own data format or plan to make one: Total Commander packer plugins rock.)
Soooo, here's the deal. We have a demo that uses a datafile, we have no clue how it looks like internally, but we'd like to chuck out all the data that's inside regardless. What we do assume however, is that the concept is the same as above - so what holds us back from assuming that we can also write the same depacker library as the coder of the demo, and hence have all the data inside neatly dumped out to our hard drive? Let's take a look inside!
The tools
For the examples below, I will use the demo "Iconolatry" by Traction, with the kind permission of Preacher / Traction. You may get the demo from here.
You will need relatively few software:
- A hex-viewer. This is what we'll be using for most of the time. I will use Total Commander's hex viewer below (press F3 on a file and press 3 to change to hex-mode.)
- A calculator with hexadecimal capabilities. Windows' calc.exe will do perfectly.
- Optionally some sort of programming interface which allows you to automate the process. This can be C, C++, Perl, PHP, anything as long as it supports the binary use of files.
Let's go.
Let's open traction_iconolatry.zip, extract data.pak and pop up the file in our hex viewer. This is what we will see:
At this point, this seems rather meaningless for us, but in fact contains all data we will need. Let's start with a simple trick: as you can see, you can clearly make out the filenames in the datafiles as they follow in a sequential order. Let's see how many files do we have then!
If you count all the filenames at the beginning of the file, you will end up with the number 55. Where do we go from here? Simple. Since we're seeing every data in hex, let's convert 55 to hex: we get 0x37. Let's take a look at our file again.

As you can see, there is a part in the file (highlighted above in red) which does have a value of 0x37, at offset 0x0C. You might be asking why the zeros next to it are highlighted, in which case I have to tell you a bit indepth: This certain demo was made for Windows, which uses the Intel CPU architecture, and consequently something which is called the "Intel byte-order" or "Little Endian". The concept of this is that when you have e.g. a 32-bit value, consisting of the bytes ABCD, it is stored in the memory as DCBA. There are pro's and con's of this concept, which we don't need to care about now, but the bottom line is this: When you write a 32-bit value into a file, it will be written backwards byte-wise.
What does this mean here? That the value "37 00 00 00" we see above in fact means "00 00 00 37" - in other words, 0x37, which is our 55. So we can safely say our first statement about the datafile: The number of the files is stored in a 32-bit value at offset 0x0C.
Ok, so we know the number of files and it's trivially visible that the first file's record starts at 0x1C, exactly one line below the number of the files. Where do we go from here?
Let's take a look at the hex dump again.
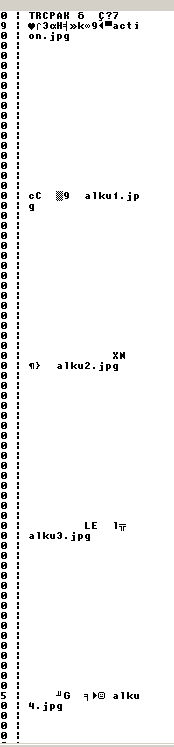
As you may notice, there's some periodicity of how the filenames follow each other. There are many ways to figure this out, but if you actually count the bytes between the first letters of the filenames, you will find out that it's always 268 bytes between each file. We can also make a statement then: A file record in this datafile is always 268 bytes long.
Putting the above together, we can also deduct the following: A start offset of a file record is always "offset(x) = 0x1C + x * 268".
So we basically have the two most important factors we need: We have our records and we know how many of them are in the file. Now comes the hard part, figuring out what all the hex bytes stand for.
Let's take a close look at the first record:

Above selected in various colours is our record. Why I already decided to share up the region in various colours is the fact that we can clearly see the three fields we need: the filename, and two 32-bit hex values. (32-bit values in this case are easily distinguishable because their upper bytes are usually zero, assuming that we don't have values over 16MB.)
So the question is, what do the values stand for?
Let's go into a bit different theory here. As the filename says, our file is a JPEG. Anyone with a bit knowledge in file signatures knows that JPEG files start with the byte sequence "FF D8 FF", and usually the string "JFIF" somewhere in the header as well. (Note: this latter is a strong assumption - digital cameras have Exif headers which omit JFIF, but in our case, it's most probably there.) So, let's look for that. Using the search function in our hex viewer, we can find some JPEG headers:

As you can see we found quite some, the above being the first four. There's one thing we have to know though - JPEG files have an ugly tendency: The thumbnails contained inside the JPEG's often have the same headers as the large files themselves, so we cannot explicitly call these headers the ones we need. So we need to think.
Let's list up what we have. We have two hex values in the header: 0x4363 and 0x39B1, and we have three sightings of a JPEG header: 0x39B1, 0x3AFD, 0x4605 and 0x7D14. We already have a match at 0x39B1, so we can make another statement: The record starts with 260 bytes that contains the filename (which is, coincidentally, the value of MAX_PATH in windows.h), and is followed by two 32-bit values, where the second is the file offset.
We have the offset, would make sense that the other value (0x4363) is the length? Let's see. offset(x) + length(x) = offset(x+1), so let's add: 0x4363 + 0x39B1 = 0x7D14, which is the fourth value we received for our JPEG-search!
So, let's add up what we know:
- The number of files is a 32-bit value at 0x000C
- The file records start at 0x001C
- Every file record is 268 bytes long.
- The file records consist of the filename (260 byte long string), the file length (4 byte long integer) and the file offset (4 byte long integer).
In other words, the pseudocode would probably look like the following for a possible ripper utility:
stream.open("data.pak")
numFiles = stream.getInt32(0x000C)
for(x = 0 to numFiles - 1)
fileHeaderOffset = 0x001C + x * 268
fileName = stream.getString(fileHeaderOffset,260)
fileLength = stream.getInt32(fileHeaderOffset+260)
fileOffset = stream.getInt32(fileHeaderOffset+260+4)
stream.saveFile(fileName,fileLength,fileOffset)
...and there you have it. You just decompiled a demo's datafile, enjoy.
Where do we go from here
Of course, this isn't always this easy. There are a couple of pitfall techniques that can lead one astray, and make the process a bit trickier:
- The file headers can be somewhere else in the file than the beginning. Solution: Look for the filenames, try to find an offset for the headers.
- The file headers can be at the end of the file. Solution: Look at the last few bytes, they might contain something useful, like size of headers or something.
- File offsets or lengths might be missing. Solution: Calculate missing data from the existing one, i.e. the length of a file is the difference between two offsets, and vice versa.
- Filenames can be variable length. Solution: Don't use direct offsets, simply traverse through the file incrementally.
- Filenames can be Unicode and hence harder to find. (I actually know only one demo doing this.)
Here are a couple of demos which might be fun to decompile because of their ease in the datafile:
- Origin by AstroideA
- Sor by Movsd
- High Voltage Win32 Port by Inquisition
- Toasted by Cubic Team & $een
Do note however, that a lot of datafiles use some sort of compression nowadays to crunch down the filesize. If you can't find any headers for the fileformats you would need in the file, you probably won't be able to find the files this easily.
Oh and if the datafile starts with "Rar!", don't bother decompiling. You know what to do.